The backend every AI app rebuilds. Shipped as one SDK.
Track every user’s cost. Enforce limits per plan. Free, Pro, daily caps, token budgets - one race-safe call, any provider. Stop rewriting the same backend for every app.
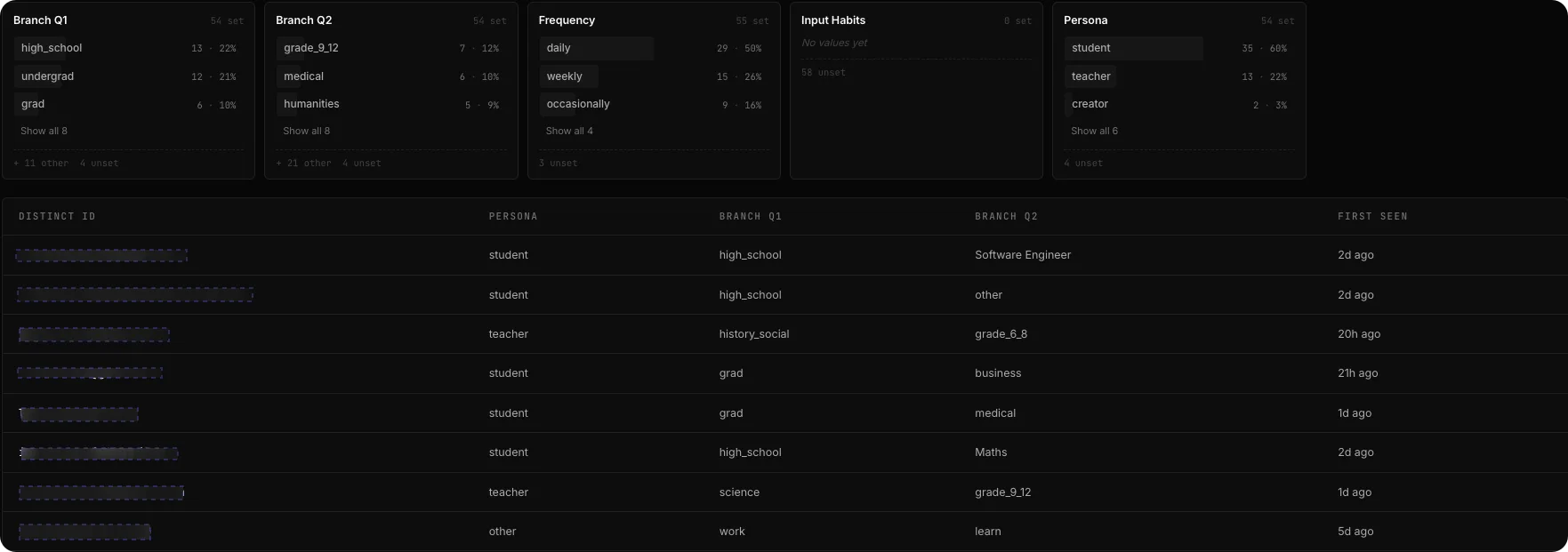
Who are your users? Which features do they live in? Bet you don’t know. Every click and every AI call joins one profile - cost, behavior, and plan in one place.
Paywalls, onboarding, emails, win-backs - written per user. Define a type once; compose() writes it from that user’s real usage and behavior. Typed output, one call.
- Latency
- ~30ms
- Providers
- Any
- Billing
- Yours
- Race-safe
- Yes ▣
You know this schema. You’ve written it before.
Six tables, every foreign key, the reserve/commit ledger that keeps parallel calls honest. Vevee ships all of it, so you wire one SDK call instead of standing up a metering backend.
- personsperson_id
- end_user_id
- PK
- traits · funnels
- first_seen · last_seen
← events · subscriptions
- eventsevt_
- id
- PK
- end_user_id
- FK
- event_type · quantity
- cost_cents · metadata
→ persons · counters
- counterscnt_
- id
- PK
- end_user_id
- FK
- limit_group
- FK
- used · period_end
→ plans & limits
- subscriptionssub_
- id
- PK
- end_user_id
- FK
- plan_id
- FK
- status · history
→ persons · plans · credit_ledger
- credit_ledgerled_
- id
- PK
- end_user_id
- FK
- delta · balance
- rollover · expires_at
→ persons
- plans & limitsplan_
- id
- PK
- limit_group
- PK
- quota · unit · period
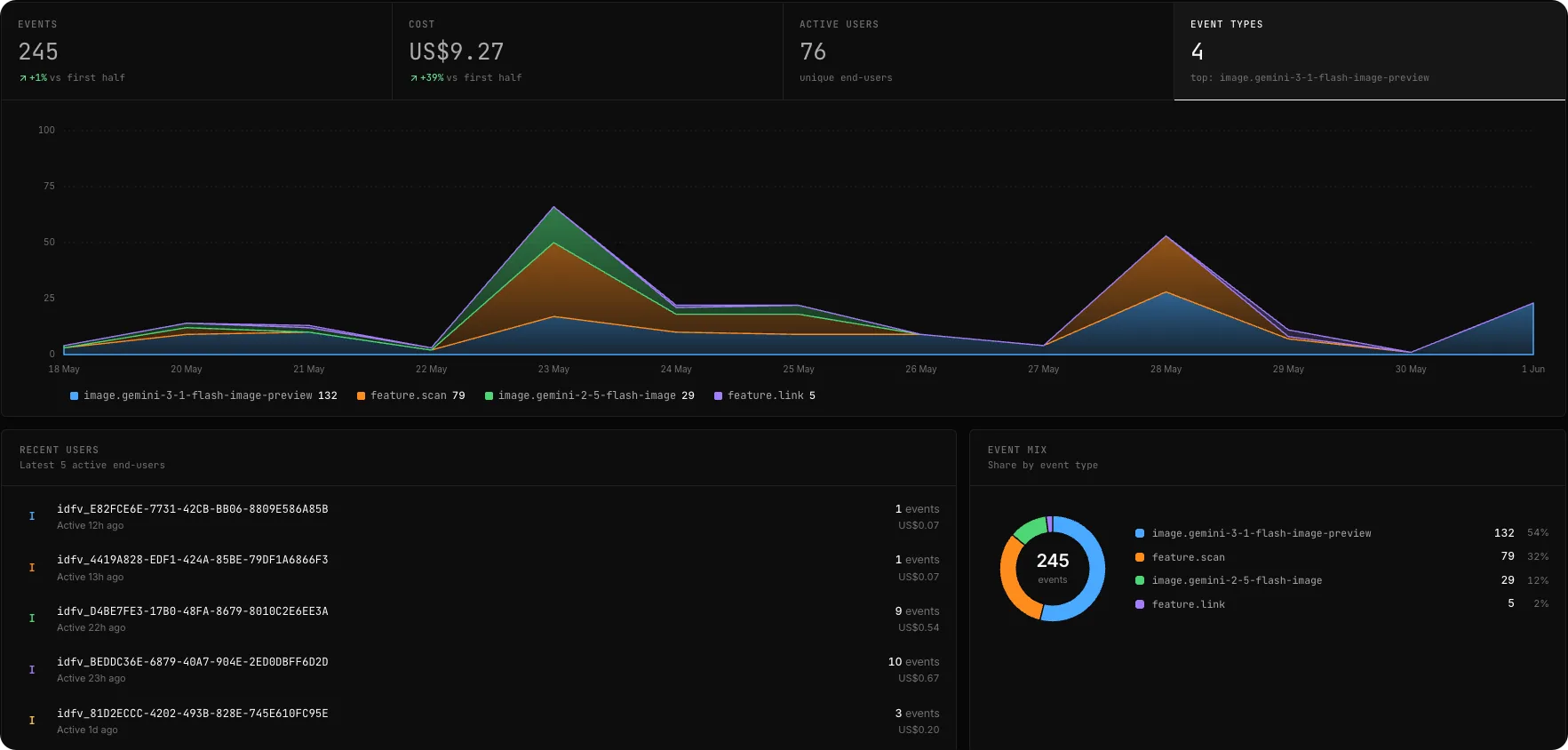
if (usage < limit) leaks under parallel calls. reserve → commit → release(60s TTL) doesn’t.Every user. What they did, what it cost, where they stand.
Stop answering “what is this user doing?” with SQL. Every event, cost, and quota joins back to one person, in one dashboard.
One compose type per job. Define it once - it writes fresh for every user.
Fifteen jobs, one API. Every card links to a full tutorial with working code.
- for your usersPersonalized paywall copy Upgrade copy grounded in each user's real usage - not a static template.
- for your usersLimit-reached upsell Answer the highest-intent moment with a nudge, not an error toast.
- for your usersOnboarding next step A different first step for every user, from their first events.
- for your usersCancel-flow save offer A save offer that names exactly what this user would lose.
Pay for usage, not seats.
One bill per account, every limit pooled across your workspaces. Start free, upgrade only when you outgrow a tier.
Your first AI feature, metered in production.
- Metering operations50k/mo
- Analytics events10k/mo
- Apps1
- Workspaces1
- AI analyzerIncluded
- Prompt logsNot included
- Media uploadsNot included
- SupportCommunity
For a launched app with paying users.
- Metering operations1M/mo
- Analytics events5M/mo
- Apps5
- WorkspacesUnlimited
- AI analyzerHigher usage
- Prompt logs30-day retention
- Media uploadsIncluded
- SupportEmail
Scale across apps and millions of calls.
- Metering operations10M/mo
- Analytics events50M/mo
- AppsUnlimited
- WorkspacesUnlimited
- AI analyzerHigher usage
- Prompt logs90-day retention
- Media uploadsIncluded
- SupportPriority
Your volume and terms, on our metering rails.
- Metering operationsCustom
- Analytics eventsCustom
- AppsCustom
- WorkspacesCustom
- AI analyzerCustom
- Prompt logsCustom
- Media uploadsIncluded
- SupportDedicated
The questions devs ask first.
How do I limit OpenAI usage per user?
Define a per-user quota in the dashboard, then wrap your call in vevee.reserve(). It returns { allowed: false } the moment a user hits their cap, before you spend a cent. Any provider, any unit.
How do I stop users from bypassing rate limits with parallel requests?
A naive if (usage < limit) check has a race condition: two requests arrive in the same millisecond, both pass, both fire. Vevee exposes a reserve → commit → release pattern with a 60-second TTL so the second request sees the first reservation. Auto-released on crash or timeout.
Does Vevee process payments or proxy my AI calls?
Neither. We never touch money: keep your billing (or none) and call upsertSubscription() from your webhook. And your code calls the model directly; we sit beside the call to gate it and record it. Prompts stay yours unless you opt in.
Which AI providers does it support?
All of them. Vevee is provider-agnostic: OpenAI, Anthropic, Gemini, Mistral, Replicate, fal, or your own self-hosted model. You decide what an event is, we meter it.
What is compose() and how is it different from a prompt I write myself?
You define the compose type once in the dashboard — a prompt plus which data it can see. Vevee runs it per user, grounded in that user's real usage and behavior, returns typed output, and meters the AI cost. You never assemble the context or build the data plumbing.
The boring backend is built. Go ship the interesting part.
Five minutes from npm install to your first enforced limit. Free to 50k ops/mo, no credit card.